
Query API : les coulisses de notre architecture CQRS serverless
Construire des read models riches dans une architecture serverless distribuée



Contexte : un back-office assurantiel 100 % cloud-native
Chez Germen, et avec notre partenaire Garance, nous avons livré le premier back-office 100 % cloud-native de gestion de plans d’épargne retraite obligatoires (PERO) sur le marché français.
Il s’agit d’une plateforme moderne, distribuée et orienté événements, pensée dès le départ pour scaler sans effort, évoluer rapidement, et surtout fournir des données fiables aux différents utilisateurs : assurés, gestionnaires et partenaires.
Pour atteindre cet objectif, nous avons dû relever un défi technique : concevoir une architecture capable d’agréger et de restituer efficacement des données distribuées, tout en garantissant la performance, la cohérence et la résilience.
Notre architecture : une plateforme distribuée et événementielle
Dès le départ, nous avons choisi une approche serverless sur AWS, bâtie autour des principes d’event-driven architecture:
Chaque microservice de notre système possède sa propre autonomie et se compose généralement de :
Une porte d’entrée de communication. Soit :
Une API Gateway pour exposer les endpoints d’entrée.
Une queue SQS pour recevoir les événements via EventBridge.
Un mécanisme de traitement de la donnée :
Des AWS Lambdas orchestrées par des Step Functions pour exécuter la logique métier.
Son propre système de stockage :
~48 microservices utilisent DynamoDB,
2 s’appuient sur RDS PostgreSQL,
et certains stockent des objets dans Amazon S3.
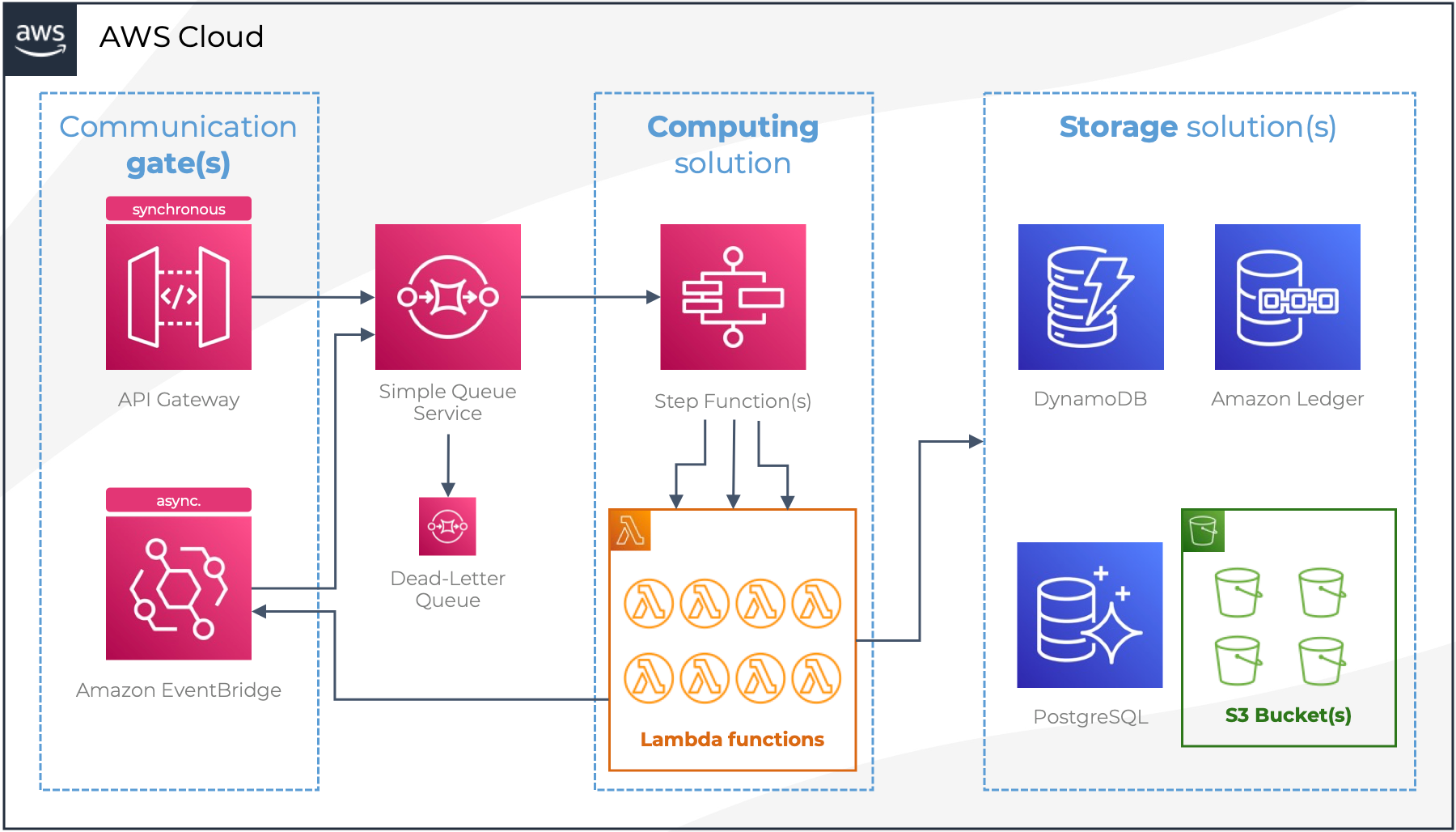
Cette approche distribuée nous donne flexibilité et scalabilité. Mais elle introduit aussi une contrainte importante : les données sont désormais dispersées dans des systèmes très hétérogènes.
Notre problématique : agréger et exposer des données distribuées
Dans une architecture de ce type, la gestion de la donnée en lecture devient vite un sujet stratégique.
Nous avions deux enjeux majeurs :
Besoins de lecture différents de ceux d’écriture.
En écriture, DynamoDB est extrêmement performant, mais en lecture, lorsque les access patterns ne sont pas connus à l’avance (spoiler : ils ne le sont presque jamais), cela devient compliqué.
Disponibilité en near-realtime.
Les données doivent être exploitables en quasi-temps réel, tout en garantissant une cohérence à terme.
Pour complexifier le tout, nos consommateurs de données sont multiples :
Des interfaces front-end utilisées par les clients finaux.
Des back-offices qui ont besoin d’une vue agrégée pour piloter les contrats.
Chacun a des besoins de lecture différents : certains veulent des vues globales, d’autres des projections filtrées, d’autres encore des recherches full-text.
La première idée (abandonnée) : l’API aggregator
Notre première approche a été d’imaginer un API aggregator, par exemple avec GraphQL, qui irait interroger directement les différentes bases de données pour chaque requête.

Cette idée, souvent utilisée dans les architectures microservices (voir Apollo GraphQL Federation), fonctionne bien sur des systèmes simples, mais elle montre rapidement ses limites :
Des problèmes de performance dès que les volumes augmentent.
Des complexités importantes pour gérer les Global Secondary Indexes (GSI) de DynamoDB.
Des schémas d’accès imprévisibles qui nécessitent une réécriture constante du code d’agrégation.
Bref, nous aurions déplacé la complexité côté API sans la résoudre réellement.
Notre solution : tirer parti de CQRS et de notre Data Lake existant
Face à ces enjeux de lecture hétérogène, de cohérence à terme et de capacité de reconstruction, nous avons naturellement cherché à nous appuyer sur un modèle architectural éprouvé : le pattern CQRS (Command Query Responsibility Segregation).
Ce paradigme, popularisé dans les architectures distribuées (voir Martin Fowler - CQRS), consiste à séparer les opérations d’écriture et de lecture dans deux systèmes distincts.
Les commandes (writes) sont traitées par les microservices et stockées dans leurs bases respectives (DynamoDB, PostgreSQL, etc.).
Les requêtes (reads) s’appuient sur des read models optimisés pour la consultation, construits à partir des données brutes ou d’événements.
Cette séparation répondait à plusieurs objectifs clés de notre architecture :
Pouvoir optimiser la lecture et l’écriture indépendamment, en dissociant les contraintes très différentes de ces deux opérations. CQRS nous permet de dimensionner et de faire évoluer chaque côté séparément, sans compromis sur les performances.
Mettre en place des vues consolidées en temps quasi-réel, en tirant parti du streaming d’événements métier pour construire des read models qui reflètent en continu l’état des systèmes.
Assurer la capacité de reconstruire nos read models à tout moment, en s’appuyant sur un historique ou un état de référence fiable en cas de migration, de perte ou de corruption de données.
Repenser le rebuild à partir d’un socle déjà en place
Au moment d’implémenter cette stratégie, nous avons réalisé que nous disposions déjà d’un atout majeur : un Data Lake opérationnel en production.
Conçu à l’origine pour des besoins de reporting et d’analyse, ce Data Lake s’appuie sur des jobs PySpark orchestrés par AWS Glue pour agréger les données issues de nos différents microservices et les exposer sous forme de tables Athena.
Plutôt que de repartir de zéro, nous avons décidé de tirer parti de cette infrastructure existante pour répondre à un besoin adjacent : la reconstruction des read models.
Ce choix présentait plusieurs avantages :
Éviter de scanner directement les bases opérationnelles (souvent coûteux et lent).
Bénéficier d’un snapshot consolidé et cohérent de nos données métiers.
Réutiliser des outils et pipelines déjà en production, sans réécrire l’existant.
PS: Nous avons exploré le pattern de mise en place d’un Event Store et d’event sourcing, mais cela ne s’est pas avéré pertinent car tous nos systèmes utilisaient des données agrégées cela aurait donc demandé une refonte conséquente de leur mode de fonctionnement.
Comment ça fonctionne concrètement
Voici un schéma d’architecture simplifié montrant le positionnement de notre read-model et son interaction avec les différents éléments de notre plateforme:
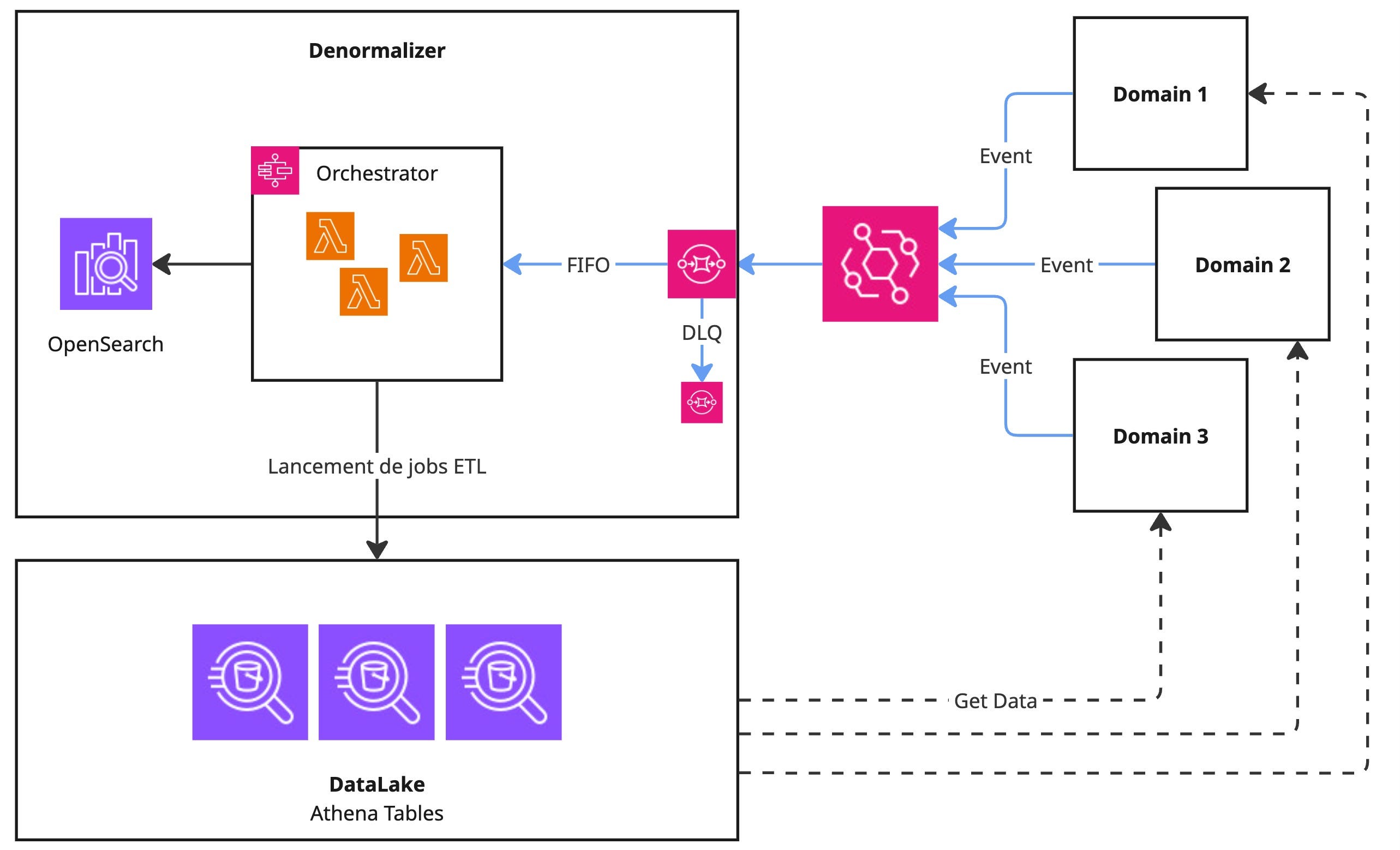
Le read-model est donc implémenté comme un module indépendant écoutant les évènements métiers et techniques de nos différents micro-services. Il utilise une queue SQS afin de traiter les messages (ou les insérer en DLQ en cas d’erreur). Ce mécanisme nous permet d’assurer la réception et traitement de nos flux en “near real-time” (flux en bleu). Lorsque cela est nécessaire, il fait appel à notre lac de données pour récupérer de la donnée structurée. Faisons un zoom sur le cœur du système permettant d’orchestrer la “denormalisation” de notre donnée.
Le pipeline (orchestrée par AWS Step Functions) repose sur quatre grandes étapes :
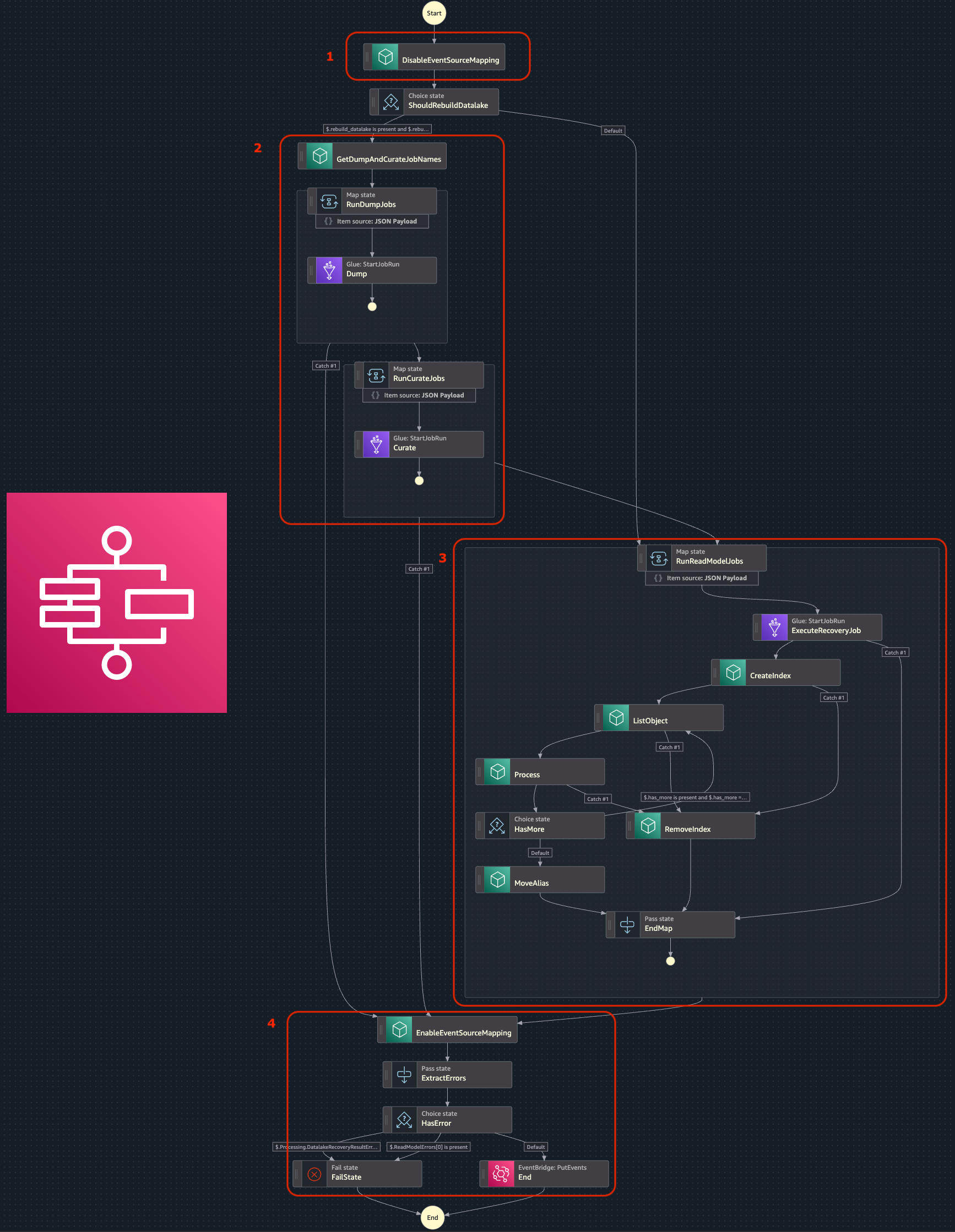
Pause contrôlée : nous stoppons temporairement la consommation des événements en coupant la queue SQS. Ceci nous permet de cumuler les événements en temps réel.
Dump et curation (optionnel) : nous utilisons AWS Glue et Athena pour extraire l’état complet des données depuis un snapshot propre quotidien.
Creation d’indexes : Parser la data, créer les modèles adaptés puis la persister sous forme d’attributs dans de nouveaux indexes. Nous créons un nouvel index nommé dynamiquement et utilisons les alias d’OpenSearch. Lorsque la reconstruction des read models est terminée, l’alias est déplacé vers ce nouvel index fraichement reconstruit. Cela nous permet de reconstruire nos index “à chaud”, sans interruption de service ni impact sur la disponibilité des lectures.
Reconstruction : nous redémarrons les consommateurs pour rejouer les événements manquants et reconstruire les read models à jour.
Ce mécanisme nous offre deux avantages majeurs :
Il permet de reconstruire facilement l’état complet du système à tout moment.
Il garantit que les données restent cohérentes et à jour même après des migrations ou incidents.
Nos limites et nos choix assumés
Nous avons fait le choix de ne pas mettre en place d’event store complet.
En théorie, l’event sourcing repose sur le stockage de tous les événements métier pour pouvoir reconstruire l’état du système.
Dans notre cas, cela aurait ajouté une complexité inutile. Les événements dont nous avons besoin sont déjà disponibles dans notre pipeline, et nous pouvons les rejouer en cas de besoin.
De plus, nous avons fait le choix de déporter les APIs consommant les modèles à chaque domaine : cela implique que notre service permet aujourd’hui que de dénormaliser la donnée en exposant l’API native d’OpenSearch. Une Query API digne de ce nom aurait eu sa propre API. Ce choix a été fait afin de permettre à chaque domaine métier de déterminer comment consommer et retourner la donnée de manière autonome.
Quelques limites actuelles / axes d’améliorations :
SQS FIFO ne traite qu’un seul message à la fois, ce qui limite le débit et lors de gros volumes impacte la rapidité d’apparition de l’information. Afin de limiter les goulots d’étranglements en conservant l’ordre des messages nous avons utilisé le nom du read model comme MessageGroupId. Les projections, ou read models, sont donc traitées en parallèle par groupe logique, chaque groupe (MessageGroupId) garantissant l’ordre strict des événements le concernant, tout en permettant un traitement concurrent entre différents read models.
Consommer directement les read models depuis le front implique d’accepter une cohérence éventuelle des données. L’optimistic design, qui consiste à anticiper le succès d’une action utilisateur, est une des réponses que nous apportons à cette cohérence éventuelle.
Conclusion
Ce projet nous a permis de poser les bases d’une architecture CQRS adaptée à un environnement serverless distribué.
Concrètement, ce que nous avons construit ici, c’est la première brique de ce modèle : le “denormalizer”, c’est-à-dire la couche qui prépare et expose les données à terme via une Query API.
Cette approche nous permet de déplacer la complexité liée à notre modèle au moment de la construction des read models plutôt que sur chaque requête. Cela nous permet d’offrir des données enrichies, cohérentes et rapides à interroger, tout en gardant la souplesse nécessaire pour faire évoluer la plateforme.
Cette architecture nous donne les moyens d’ajouter de nouveaux événements métier ou de nouveaux besoins fonctionnels de façon incrémentale, sans refactorer l’existant. Et lorsque des changements structurels majeurs interviennent, nous pouvons reconstruire les modèles de lecture à partir de zéro sans impacter la production.
 |
|